Control IBM i jobs that use excessive temporary storage or CPU seconds
In previous blog articles I’ve made the case for preemptive problem solving – anticipating potential problems before they happen and taking steps to lessen their effect when they do happen.
In particular I’ve discussed how watch-for-event-functions and the IBM i Query Supervisor can be configured to alert you to issues before they become big problems.
Watch-for-event-functions can be used to watch for messages such as when a journal receiver is changed and then check that the journal receiver sequence is not about to exceed system limits – giving you the ability to check that the journal sequence can be reset properly.
The Query Supervisor can check if a query is using too much temporary storage or CPU – you could then hold the query and alert your support personnel to investigate and take the appropriate action before it becomes a big problem – disk space filling up and stopping the system.
This article continues in the same vein: the importance of anticipating problems and taking preemptive measures to ensure they don’t get out of hand.
The Query Supervisor is great for monitoring SQL or query type jobs but what about other types of jobs, that are not query based? Can we automatically monitor those for excessive resource consumption? Absolutely, this article shows how you can control any job that is consuming too much temporary storage or too many CPU seconds and take action on it before it becomes a big problem.
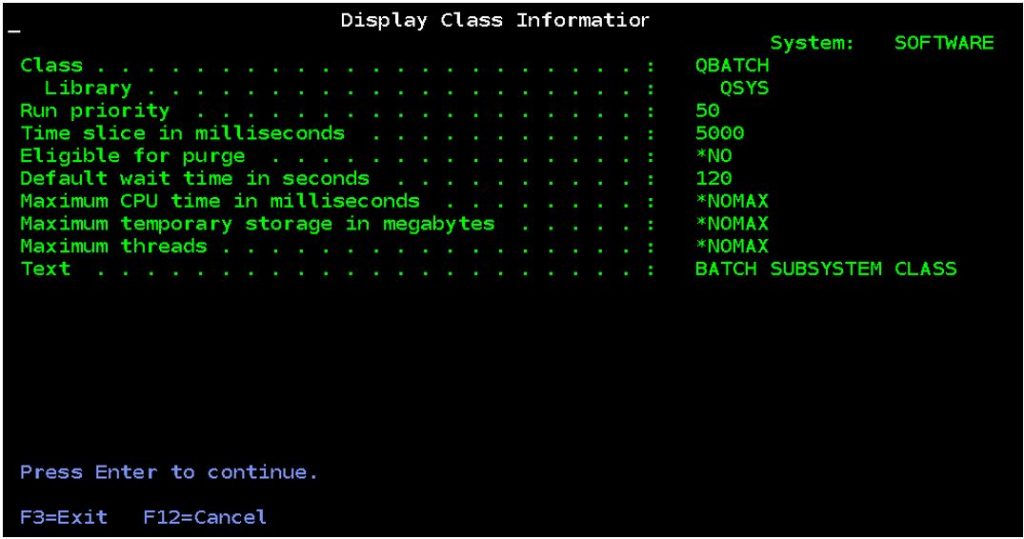
This control uses configuration settings in the class objects used by jobs. A class object is used by every job and basically supplies each job with performance-related configuration settings such as the job’s run-priority.
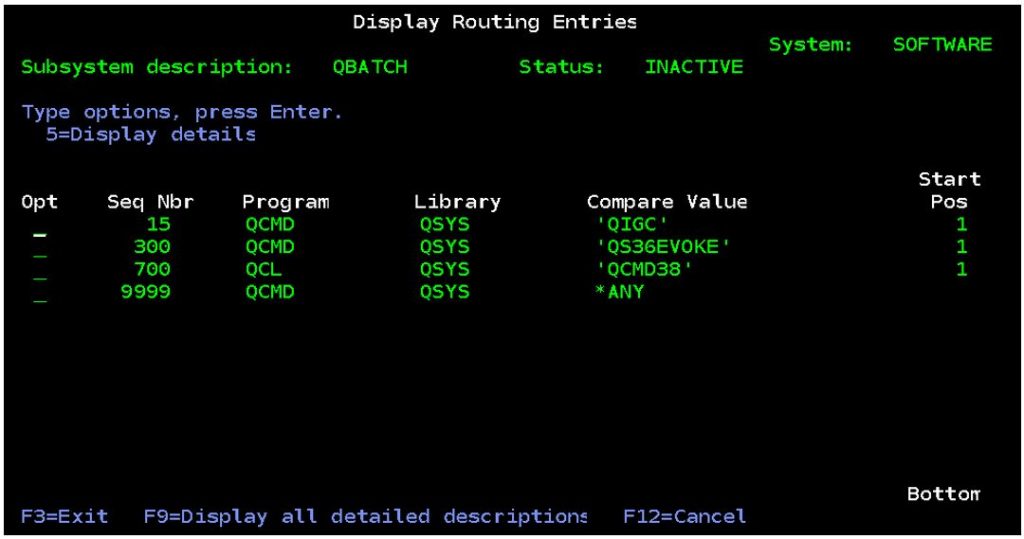
Without getting too deep into work management the class used for each job is determined within the subsystem description configuration. For prestart jobs the class is determined in the prestart job entry. For other types of jobs the class is determined by the relevant routing entry.
So, for example, if we submit a job to the QBATCH subsystem using default parameters the routing entry used will be sequence number 9999. The relevant routing entry is found by comparing the routing data (the default routing data in the SBMJOB command is ‘QCMDB’) with the compare values of the routing entries in the subsystem. There is no corresponding routing entry with compare value ‘QCMDB’ but there is a catch-all one for *ANY. This is how the routing entry for sequence number 9999 gets selected. Within that routing entry we see that the class object is QSYS/QBATCH.
So, to limit the amount of temporary storage used by the job using this class run the following command:
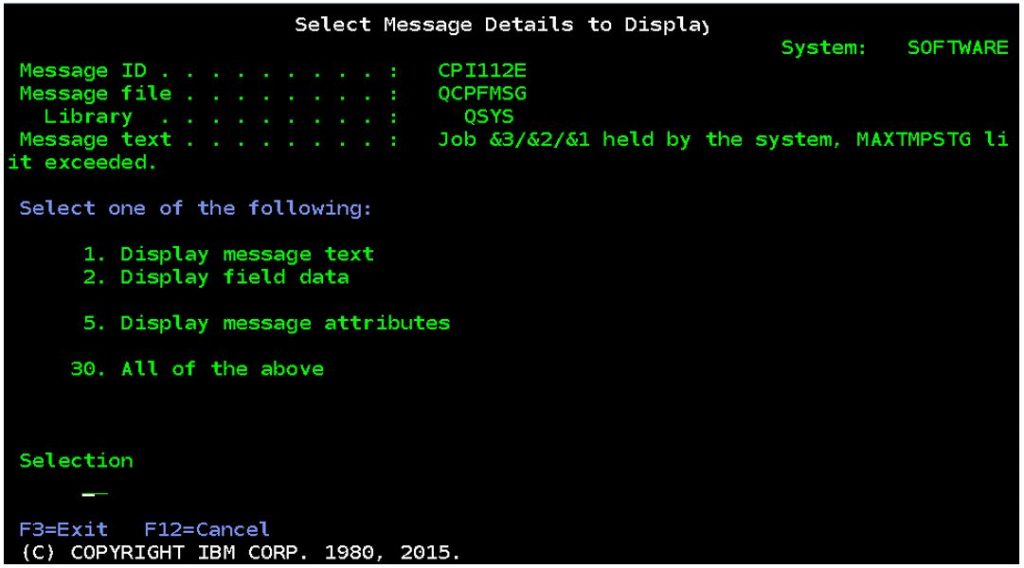
When this change is made (default is no maximum temporary storage) and a job exceeds that amount of temporary storage, message CPI112E is sent to the QSYSOPR message queue and the relevant job is held.
To limit the amount of CPU time used by the job using this class run the following command:
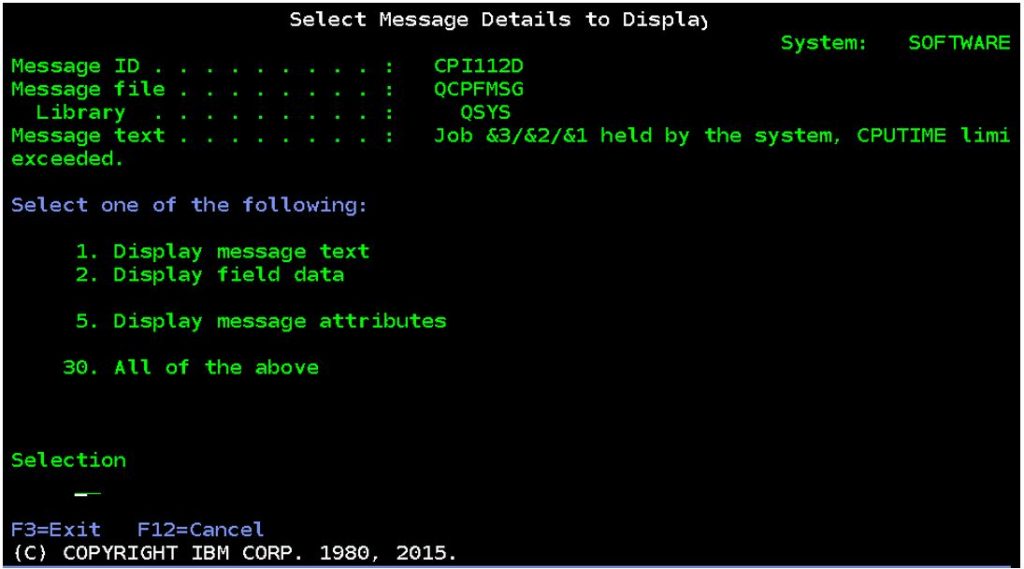
When this change is made (default is no maximum CPU time) and a job exceeds that amount of CPU time, message CPI112D is sent to the QSYSOPR message queue and the relevant job is held.
In both cases this requires close monitoring of the QSYSOPR message queue and the relevant action taken, such as to release or end the job. You will not be able to release the job until either the temporary storage or CPU time limit has been increased using the chgjob command as in the following examples.
An important thing to remember is that the above configuration changes will affect every job that uses the changed class object. The temporary storage and CPU time requirements will probably vary greatly between different types of jobs. Therefore, you will want to create your own classes for different jobs and configure your subsystems to use them so that all jobs get controlled correctly.